P-HRTF: Efficient Personalized HRTF Computation
for High-Fidelity Spatial Sound
Alok Meshram
Ravish Mehra
Hongsheng Yang
Enrique Dunn
Jan-Michael Frahm
Dinesh Manocha
University of North Carolina at Chapel Hill
|
Abstract
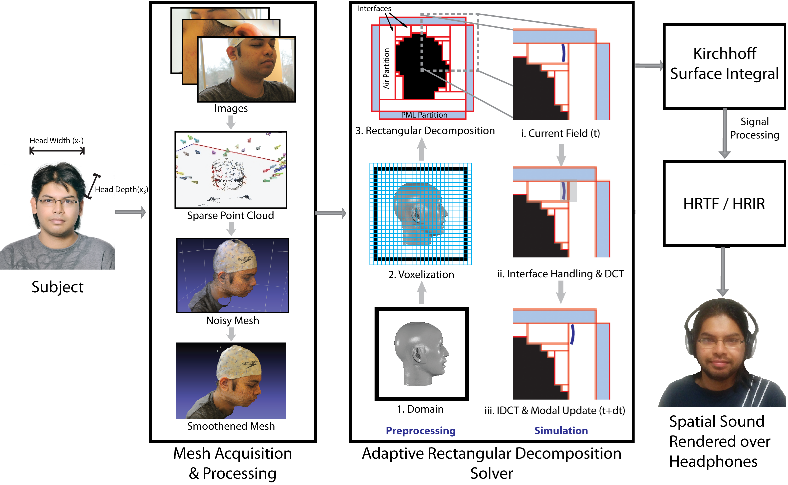
Accurate rendering of 3D spatial audio for interactive virtual auditory displays requires the use of personalized head related transfer functions (HRTFs). We present a new approach to compute personalized HRTFs for any individual based on combining state-of-the-art image-based 3D modeling with an efficient numerical simulation pipeline. Our 3D modeling framework enables capture of the listener's head and torso using consumer-grade digital cameras to estimate a high resolution non-parametric surface representation of the head, including extended vicinity of the listener's ear. We leverage sparse structure from motion and dense surface reconstruction techniques to generate a 3D mesh. This mesh is used as input to a numeric sound propagation solver which uses acoustic reciprocity along with Kirchhoff surface integral representation to efficiently compute the personalized HRTF of an individual. The overall computation takes tens of minutes on multi-core desktop machine. We have used our approach to compute personalized HRTFs of few individuals and present preliminary evaluation. To the best of our knowledge, this is the first commodity technique that can be used to compute personalized HRTFs in a lab or home setting.

Alok Meshram, Ravish Mehra, Hongsheng Yang, Enrique Dunn, Jan-Michael Frahm, and Dinesh Manocha.
P-HRTF: Efficient Personalized HRTF Computation
for High-Fidelity Spatial Sound
Video (MP4, 12 MB)

Alok Meshram, Ravish Mehra, and Dinesh Manocha.
Efficient HRTF Computation using Adaptive
Rectangular Decomposition
Acknowledgement
We would like to thank Dr. Yuvi Kahana and Insitute for Sound and Vibration Research (ISVR), University of Southampton, UK, for the scanned 3-D mesh of the KEMAR manikin and DB-60 pinna as well as Dr. Ramani Duraiswami and Dr. Dmitry Zotkin at University of Maryland, USA, for the scanned 3-D mesh and HRTFs of the Fritz manikin.