MixedPeds
Pedestrian Detection in Unannotated Videos using Synthetically Generated Human-agents for Training
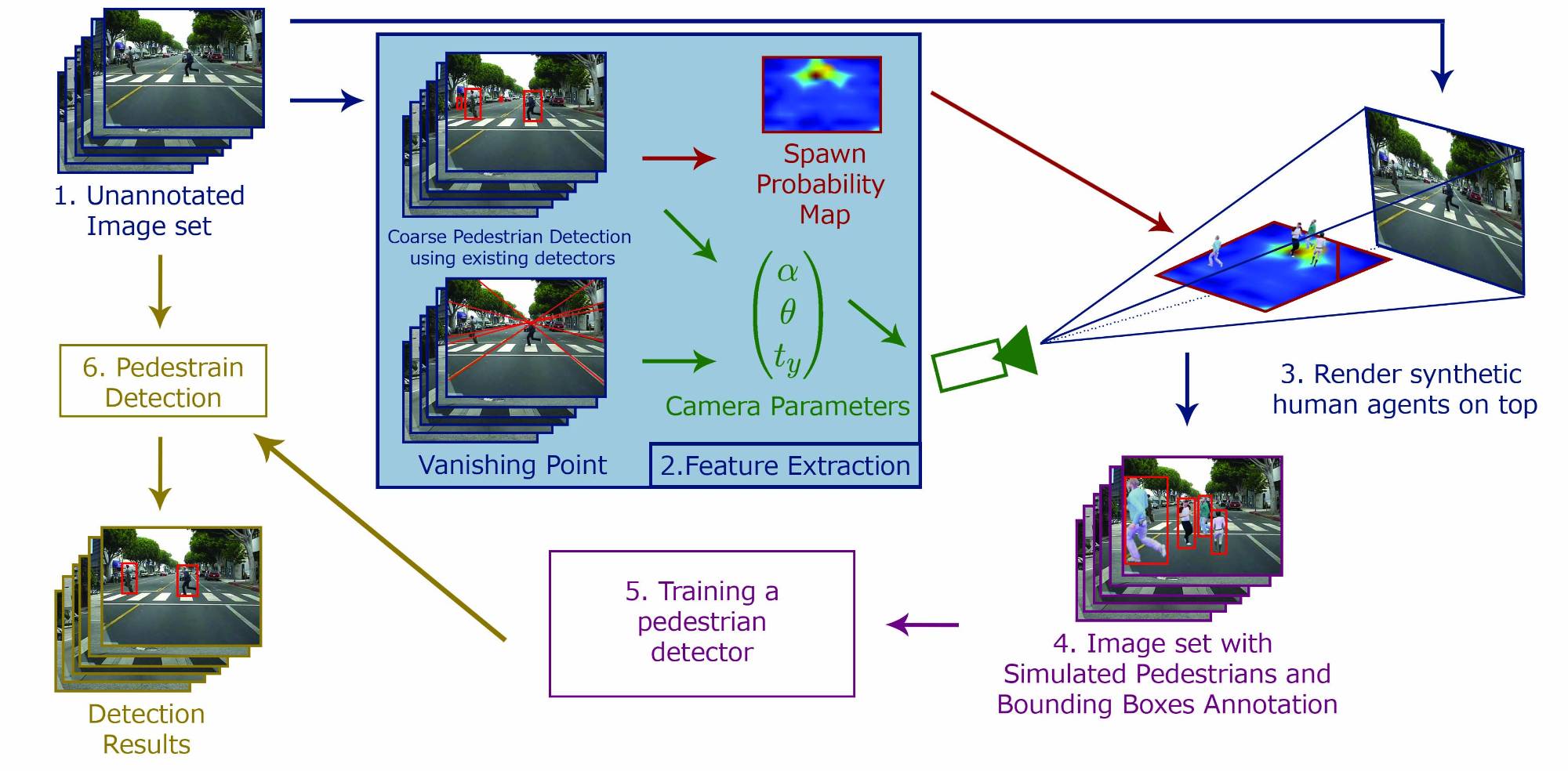
Pedestrian Detection in Unannotated Videos using Synthetically Generated Human-agents for Training
We present a new method for training pedestrian detectors on an unannotated set of images. We produce a mixed reality dataset that is composed of real-world background images and synthetically generated static human-agents. Our approach is general, robust, and makes few assumptions about the unannotated dataset. We automatically extract from the dataset: i) the vanishing point to calibrate the virtual camera, and ii) the pedestrians' scales to generate a Spawn Probability Map, which is a novel concept that guides our algorithm to place the pedestrians at appropriate locations. After putting synthetic human-agents in the unannotated images, we use these augmented images to train a Pedestrian Detector, with the annotations generated along with the synthetic agents. We conducted our experiments using Faster R-CNN by comparing the detection results on the unannotated dataset performed by the detector trained using our approach and detectors trained with other manually labeled datasets. We showed that our approach improves the average precision by 5-13% over these detectors.