
The shipping, pivot and torpedo models (courtesy: Electric Boat)
Graphics systems have made significant advances in polygon rendering capabilities. However many models are more conveniently represented and manipulated using more general representations, e.g. non-uniform rational B-spline (NURBS) surfaces. This class includes Bézier surfaces and other rational parametric surfaces like tensor product and triangular patches. Large scale sculptured models consisting of thousands of such surfaces are commonly used to represent shapes of automobiles, submarines, airplanes, building architectures, sculptured models, mechanical parts and in applications involving surface fitting over scattered data or surface reconstruction. Real time rendering of sculptured models for applications involving virtual worlds and other immersive technologies remains a difficult problem.
We have been working on fast and accurate algorithms to display NURBS surfaces (trimmed and non-trimmed). We polygonize the sculptured models and render them using the capabilities of current graphics systems. The NURBS models (e.g. the dragon model) are decomposed into Bézier surfaces (Bernstein basis) and each Bézier surface is tessellated uniformly in its parametric domain. The criteria for this tessellation are based on the sizes of triangles and their deviation from the surface in the screen space. This involves the calculation of bounds on derivatives and an estimation of curvatures of the surface. Our method improves the way these bounds are calculated and generates fewer triangles.
The main new features of our approach are:
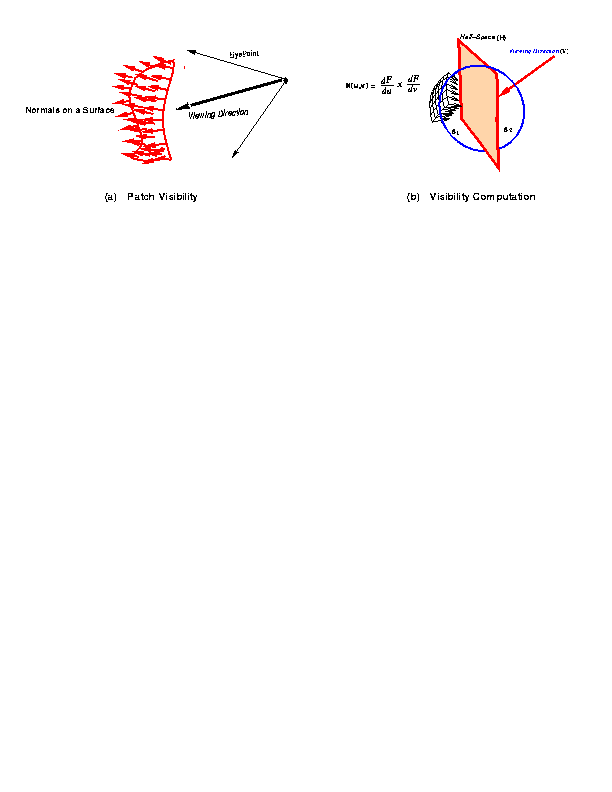
We introduce techniques to discard patches facing away from the viewing direction, aka back face culling of triangles. The model is organized in a hierarchical spatial data structure. This enables fast culling of group of patches under a spatial node, which lies outside the view frustum. This also allows us to eliminate considerable portion of the models from rendering overhead. We use the coherence of image from frame to frame to speed up the rendering. Only incremental computation is performed to update the triangulation of surfaces at each frame. Most of the triangles used for a frame are reused in the next frame. We prevent cracks in our rendered images by using the idea of coving and tiling introduced by Rockwood et al. at patch boundaries. We solve the problem of cracks at trimmed curves by maintaining a multi-resolution representation of the trim curves. The idea is to use the space representation of the curve to estimate the required tessellation.
For triangulating the trimmed surfaces we draw the trim curves on the uniform tessellation mesh, leaving out the triangles totally trimmed out and cutting the triangles that are partially trimmed. Only the points that are in the final triangulation are evaluated.
In the hierarchy of bounding volumes used for view frustum culling, as described above, each leaf node consisting of a set of Bezier patches, define a super-surface. Dynamic tessellation of the interior of each visible super-surface, and feeding this triangular approximation of the super-surface to polygonal simplification algorithm, would result in various discrete levels of detail of the model. This dynamic tessellation is based on the coherence as described above. The boundary of each super-surface is tessellated statically to eliminate cracks in the rendering. Both triangular approximation and the polygonal simplification are done within the user defined error bounds from the original spline surface.
We achieve low latency and smooth motion in our interactive spline model rendering, by the parallel implementation of various algorithms in our system, like dynamic tessellation, visibility computation etc. This implementation, also decouples triangle rendering from triangle generation using frame-to-frame coherence. We use a lock-free dynamic load-balancing technique to distribute super-surfaces to various processors in the multiprocessing environment.
Our implementation on an SGI Onyx with three 200 MHz R4400 CPUs and a Reality Engine graphics accelerator, has a performance of 40,000 Bézier patches at 7-15 frames per second. The models tested in our system, include the Yuan Ming garden model and the the output of BOOLE B-rep solid modeling system, developed at UNC. We have achieved a performance of rendering up to 450,000 on-screen Bézier primitives per second. On the SGI Onyx, our system improves the performance of the native NURBS GL primitives by more than an order of magnitude.
For more information, contact:
Check out our Papers and technical reports.
This research is supported by DARPA ISTO order A410, NSF grant MIP-9306208, Alfred P. Sloan Foundation Fellowship, University Research Award, ARO contract P-34982-MA, NSF grant CCR-9319957, ARPA contract DABT63-93-C-0048, NSF/ARPA Science and Technology Center for Computer Graphics and Scientific Visualization, NSF Prime contract 8920219, and ONR contract N00014-94-1-0738.
{kind=link}
{kind=link}
{kind=link}