GPUFFTW versus cfft1d()on the CPU
We have observed considerable speedups with GPUFFTW over Intel Math Kernel library running on high-end multi-core CPUs. The following graph shows the compute timings for two test systems with high-end $1500-$2000 CPUs. Note that in both cases, GPUFFTW performs considerably faster. The cfft1d routine in the Intel Math Kernel library uses four threads to exploit the four available processors on the dual Opteron 280 processors and the dual 3.6 GHz HT Xeon processors. In practice, using the FFTW metric, our algorithm is able to achieve 29 GFLOPS of computational performance on a NVIDIA 8800 GTX GPU.
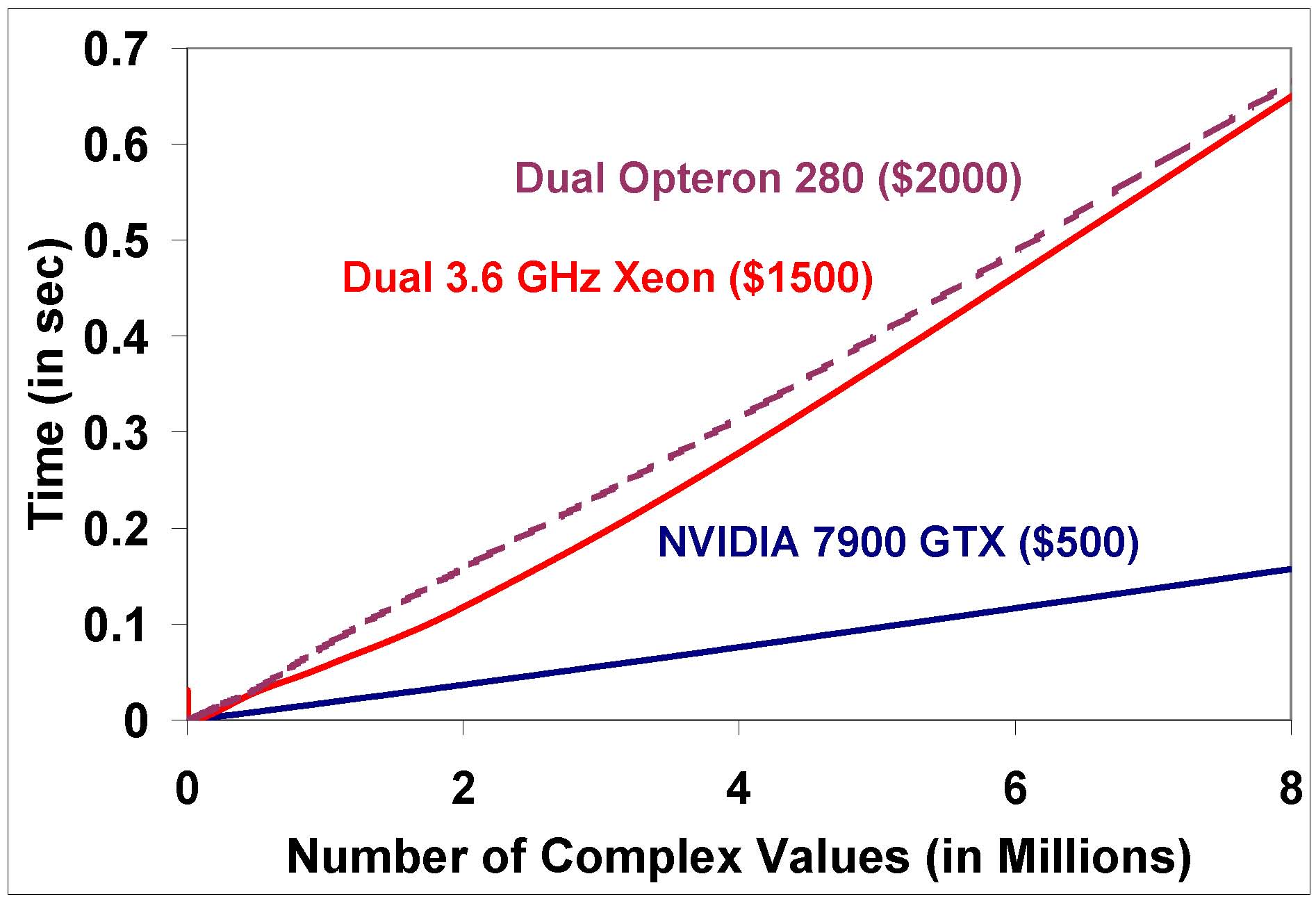 |
Comparison of GPUFFTW with previous approaches for performing 1D FFTs on the GPU
We have also compared the performance of GPUFFTW and libgpufft on a NVIDIA 7800 GTX GPU. Our algorithm uses stockham autosort whereas libgpufft is implemented using the BrookGPU compiler and uses an improved version of Cooley-Tukey FFT algorithm. Our results indicate a 3x performance improvement over libgpufft.