We present a novel algorithm to solve dense linear systems using graphics processors (GPUs). We reduce matrix decomposition and row operations to a series of rasterization problems on the GPU architecure. These include new techniques for streaming index pairs, swapping rows and columns and parallelizing the computation to utilize multiple vertex and fragment processors. We also use appropriate data representations to match the rasterization order and cache technology of graphics processors. We have implemented our algorithm on different GPUs and compared the performance with optimized CPU implementations. In particular, our implementation on a NVIDIA GeForce 7800 GPU outperforms a CPU-based ATLAS implementation. Moreover, our results show that our algorithm is cache and bandwidth efficient and scales well with the number of fragment processors within the GPU and the core GPU clock rate. We use our algorithm for fluid flow simulation and demonstrate that the commodity GPU is a useful co-processor for many scientific applications.
In Proceedings of the ACM/IEEE SC|05 Conference. November 12-18, 2005. Download: Paper Slides
 |
 |
|---|---|
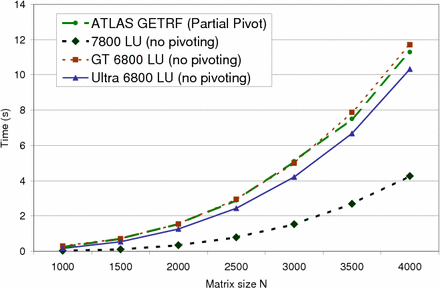
Average running time of LU-matrix decomposition without pivoting as a
function of matrix size: This graph highlights the performance obtained by our algorithm
on three commodity GPUs and ATLAS getrf() on a high-end 3.4GHz Pentium
IV CPU. Note that the performance of our algorithm without pivoting is comparable to
the optimized ATLAS getrf() implementation of LU decomposition with pivoting.
Furthermore, the CPU and GPU algorithms indicate an asymptotic O(n^3) algorithm
complexity. |
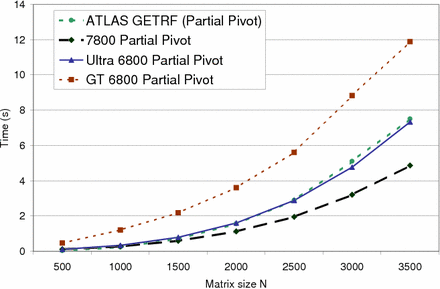
Average running time of a LU-matrix decomposition with partial pivoting as a function of the matrix size. Our algorithm is compared to ATLAS getrf() for three commodity GPUs. Note that our implementation is 35% faster for matrix size 3500 on the fastest GPU, and that our algorithm follows ATLAS' execution time growth rate closely. |
 |
 |
|---|---|
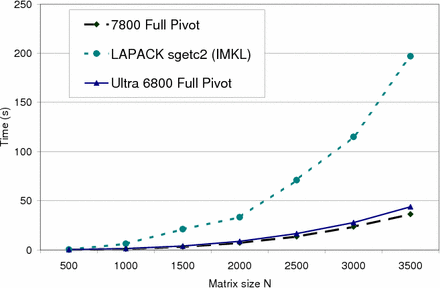
Average running time of one matrix decomposition with full pivoting in
function of matrix size. Our algorithm is an order of magnitude faster than the implementation
of LAPACK getc2() in the Intel Math Kernel Library (IMKL). |
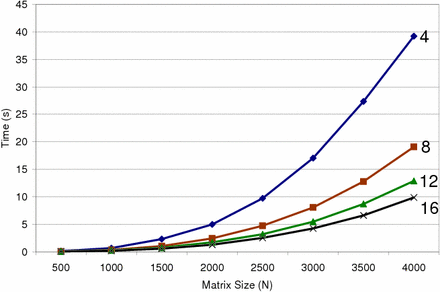
Average running time of LU matrix decomposition without pivoting, for different number of parallel fragment processors disabled in a NVidia 6800 Ultra GPU, in function of matrix size. The number of fragment processors associated with each data curve is shown on the right. The data shows almost linear improvement in the performance of our algorithms as the number of fragment processors is increased. |
We map the problem to the GPU architecure based on the observation that the fundamental operations in matrix decomposition are elementary row operations. Our specific contributions include:
- Two-dimensional data representation that matches the two dimensional cache layout of the GPUs.
- High utilization of graphics pipeline and parallelization by rendering large uniform quadrilaterals
- Index pair streaming with texture mapping hardware.
- Efficient row and column swapping by parallel data transfer.
These techniques and underlying representations make our overall algorithm cache and bandwidth efficient. We avoid potentially expensive context switch overhead by using appropriate data representations. We also propose a new technique to swap rows and columns on the GPU for efficient implementation of partial and full pivoting. We apply our algorithm to two direct linear system solvers on the GPU: LU decomposition and Gauss-Jordan elimination. We benchmarked our implementation on two generations of GPUs: the NVIDIA GeForce 6800 and the NVIDIA 7800, and compared them with the CPU-based implementation on a 3.4GHz Pentium IV with Hyper-Threading. The implementation of our GPU-based algorithm on the GeForce 6800 is on par with the CPU-based implementation for matrices of size 500x500 and higher. Our implementation on the NVIDIA GeForce 7800 GPU outperforms the ATLAS implementation significantly.