This page briefly describes spatial video encoding in the context of interactive architectural walkthrough and provides links to a relevant paper and some video footage of the system described therein.
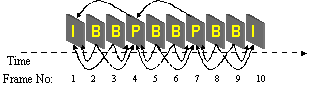
Video encoding schemes such as MPEG and MPEG-2 achieve much of their compression by exploiting coherence between one image and the next in a temporal sequence. This scheme assumes a linear sequence in the images: that is, frame N+2 is displayed after frame N+1 is displayed after frame N.
We want to apply the same sort of compression (detection and efficient representation of frame-to-frame coherence) to images with arbitrary spatial relationships. This leads to more than one choice of "next frame": for example, if we have captured images from a set of viewpoints in space, it may be perfectly reasonable to request a frame's east neighbor as the next frame, then the north neighbor, then the upward neighbor. These structures map poorly onto the 1D structure of traditional MPEG video (see this paper for an investigation).
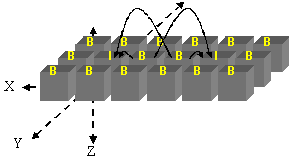
It turns out that the spatial relationships between the images informs the encoding. Full details are in the paper, but here's the intuition: by making temporal references explicit in our video format, we can exploit coherence in any nearby frame in any direction. We choose to organize our database into macrocubes, similar in concept to MPEG macroblocks, and code outlying images in those macrocubes (the B cubes in the image below) from the two nearest I cubes in space.
|
|
| Traditional MPEG video: frames are organized in a linear temporal sequence. Arrows indicate temporal dependencies: frame 4 is coded using frame 1, frame 5 is coded using frames 4 and 7, etc. I-frames are encoded without temporal information, P-frames are encoded from the nearest preceding I- or P-frame, and B-frames use information from the nearest I- or P-frame in both the past and the future. | Spatial MPEG video: frames are organized along spatial dimensions. I-cubes are encoded without exploiting coherence. There are (currently) no P-cubes. B-cubes are encoded using information from the nearest two I-cubes in space. |
We use spatially encoded video to represent distant geometry in a cell-based architectural walkthrough system. During preprocessing, we render many views of a target environment from known viewpoints and capture camera information as well as both frame and depth buffers for each view. These images are organized in a 3D array and encoded as described in the paper. Since we have depth and camera information, we can also compute optical flow during encoding. This allows us to substantially accelerate motion-vector search, traditionally one of the most time-consuming phases of video encoding. At runtime, images are decoded from the resulting video database to be used as impostors for distant geometry. See the paper for details.
We presented the paper "Spatially Encoded Far-Field Representations for Interactive Walkthroughs" at ACM Multimedia 2001. An HTML version of the paper may be found in the MM2001 Electronic Proceedings or downloaded from this web page as a PDF (573Kb). This paper received the best paper award at the ACM Multimedia 2001 Conference.
Andy Wilson, Dinesh Manocha, Ketan Mayer-Patel
Department of Computer Science
CB 3175, Sitterson Hall
University of North Carolina
Chapel Hill, NC 27599-3175
USA
awilson@cs.unc.edu (Andy Wilson)
kmp@cs.unc.edu (Ketan Mayer-Patel)
dm@cs.unc.edu (Dinesh Manocha)