 |
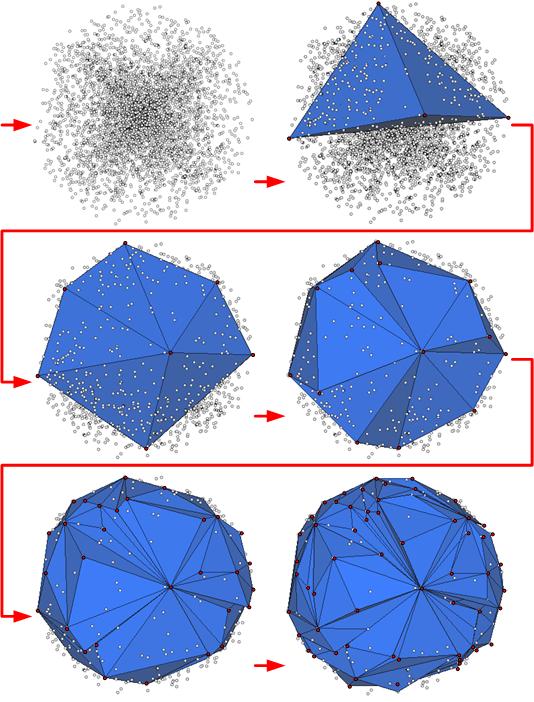
| Interior point culling filter: For the input points, a tetrahedron is constructed as an initial pseudo-hull. Each facet of the pseudohull is updated by replacing it with three new facets. Each of these new facets is computed by connecting the edges of the old facet with the furthest point in the exterior set. All the points inside the expanding pseudo-hull are marked as interior points. After 4 iterations, most of the interior points are culled away. The pseudo-hull is incrementally updated till there are no exterior points. |
|
|
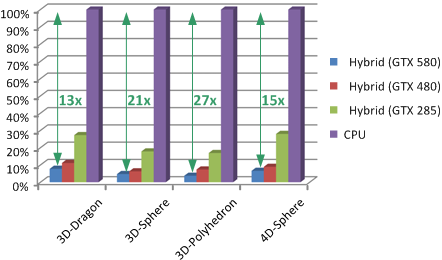
| Performance comparison: Comparing to the optimized CPU-based implementation, our hybrid CPU-GPU algorithm achieves 13-27x speedups over the CPU-based QuickHull algorithm on an NVIDIA GeForce GTX580 for all these static benchmarks. |
|
|
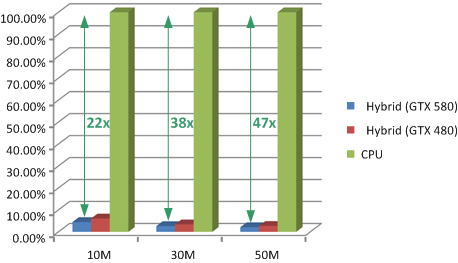
| Performance comparison: By testing on 10M, 30M, and 50M points that are randomly distributed in a spherical 3D space, the hybrid algorithm demonstrates higher speedup over the CPU-based algorithm as the size of the point-set increases. |
 |
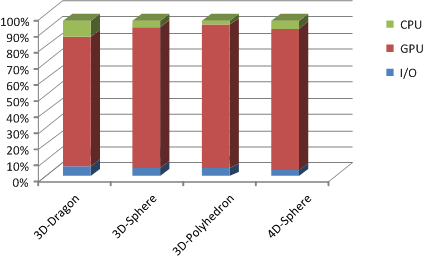 |
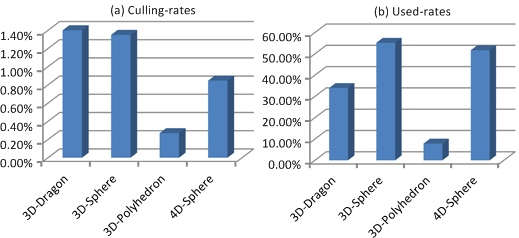
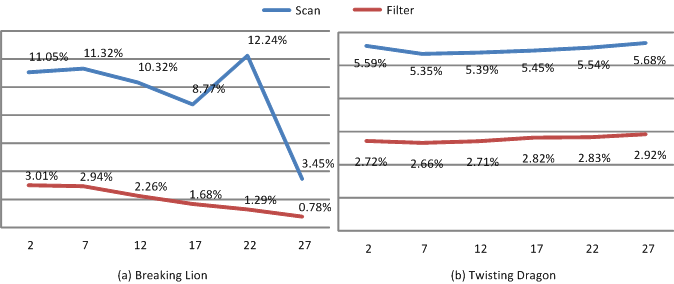
| Culling Efficiency: By running the pseudo-hull filter, less than 5% of the original input points are not culled. As a result, the input size, in terms of points, to the final CPU-based computation algorithm is relatively small. | Running time ratios: The figure shows the breakdown of each phase of the hybrid algorithm on different benchmarks. Basically, this breakdown indicates that a majority of the overall time is spent in the GPU-based interior point filtering algorithm on these benchmarks. The time spent in data-transfer and CPU-based algorithm is relatively small. |
 |
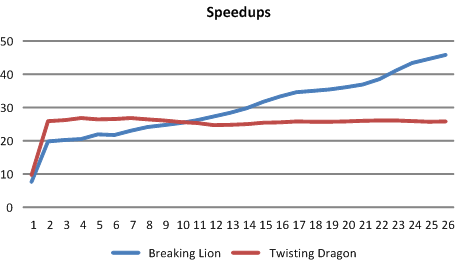 |
| Culling efficiency for deforming point sets: By utilizing the spatial and temporal coherence between successive simulation time steps, a scan pass is performed to reuse pseudo-hulls at last simulation time step and remove interior points. Another pass is performed for interior point culling. | Speedups for deforming point sets: With the help of the light-weighted scan pass, the hybrid algorithm achieved up to 46x speedups for deforming point sets. |
Abstract
We present a hybrid algorithm to compute convex hull of points in three and higher dimensional spaces. Our formulation uses a GPU-based interior point filter to cull away many of the points that do not belong to the boundary. The convex hull of remaining points is computed on the CPU. The GPU-based filter proceeds in an incremental manner and computes a pseudo-hull that is contained inside the convex hull of the original points. The pseudo-hull computation involves only localized operations and therefore, maps well to GPU architectures. Furthermore, the underlying approach extends to high dimensional point sets and deforming points. In practice, our culling filter can reduce the number of candidate points by two orders of magnitude. We have implemented the hybrid algorithm on commodity GPUs, and evaluated its performance on several large point sets. In practice, the GPU-based filtering algorithm can cull up to 85M interior points per second on NVIDIA GeForce GTX 580 and the hybrid algorithm improves the overall performance of convex hull computation by 10-27 times (for static point sets) and 22-46 times (for deforming point sets).
Contents
Paper (PDF 1.08 MB)
Min Tang, Jie-yi Zhao, Ruofeng Tong, and Dinesh Manocha, GPU accelerated Convex Hull Computation, Accepted by SMI 2012, 2012.